Understanding Transformer Architecture: The Encoder-Decoder Context Revolution in AI
- RAHUL KUMAR
- Aug 20, 2025
- 5 min read

The Transformer architecture has fundamentally revolutionized how artificial intelligence understands and generates human language. At its core, the Transformer's encoder-decoder structure represents a breakthrough that enables modern language models like GPT, BERT, and countless other AI systems to process text with unprecedented accuracy and contextual understanding.
Basic schematic of the attention mechanism showing input-to-output relationships in deep learning models

What is a Transformer?
A Transformer is a neural network architecture specifically designed to handle sequential data, particularly text, by processing entire sequences in parallel rather than word-by-word. Unlike traditional models that analyze text sequentially, Transformers use an innovative attention mechanism that allows them to understand relationships between all words in a sentence simultaneously.
The original Transformer, introduced in the groundbreaking 2017 paper "Attention is All You Need," consists of two main components: an encoder that processes input text and a decoder that generates output text. This encoder-decoder architecture forms the foundation for most modern language AI systems.

Diagram illustrating the neural self-attention mechanism in transformer models, showing the flow from input tokens through queries, keys, values, scaled dot-product attention, and final output
The Encoder: Understanding Input Context
Architecture Overview
The encoder serves as the comprehension engine of the Transformer. Its primary responsibility is to process the input sequence and create rich, contextual representations that capture the meaning and relationships within the text.
The encoder consists of six identical layers stacked on top of each other. Each layer contains two essential components:
Multi-Head Self-Attention Mechanism: This allows the model to examine every word in the input while processing any given word. For example, when processing the word "bank" in "I went to the bank," the attention mechanism helps determine whether it refers to a financial institution or a riverbank by looking at surrounding context.
Feed-Forward Neural Network: After attention processing, each word's representation passes through a fully connected network that applies additional transformations to capture more complex features.
How Self-Attention Works
Self-attention is the revolutionary mechanism that enables Transformers to understand context. The process involves three key components:
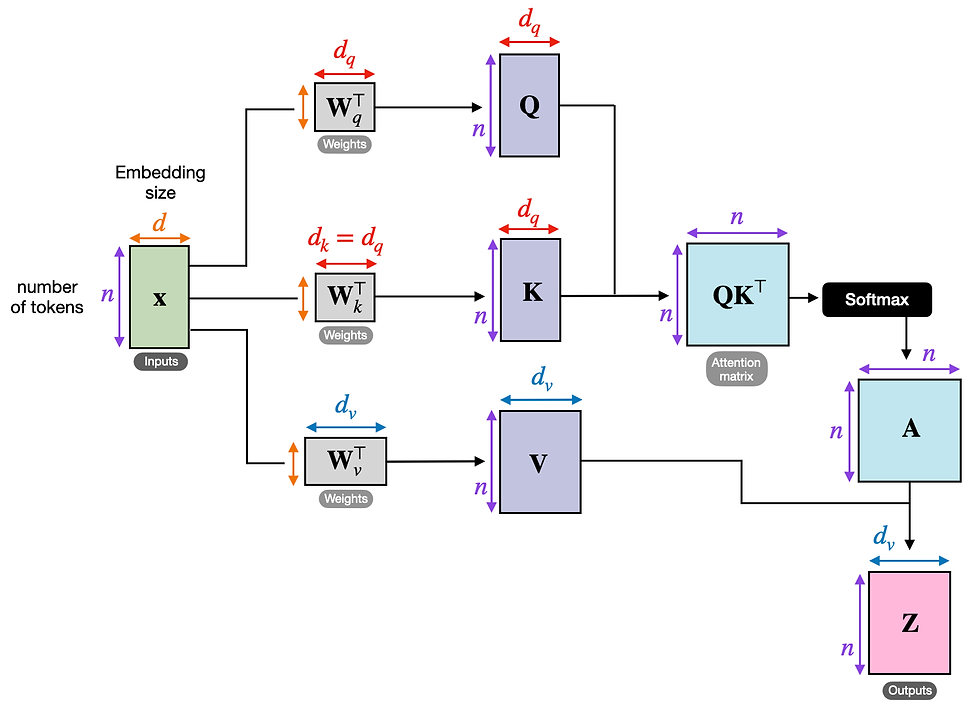
Diagram illustrating the self-attention mechanism in transformer models, showing inputs, queries, keys, values, attention matrix, and outputs with dimensional annotations
Query, Key, and Value Vectors: For each word, the system creates three different vector representations:
Query (Q): Represents what the current word is "asking" about
Key (K): Represents what information each word contains
Value (V): Represents the actual information to be retrieved
Attention Score Calculation: The model computes how much attention each word should pay to every other word by calculating the dot product between Query and Key vectors.
Weighted Information Aggregation: Using these attention scores, the model creates a weighted combination of Value vectors, ensuring that relevant context influences each word's final representation.
Positional Encoding
Since Transformers process all words simultaneously, they need a way to understand word order. Positional encoding solves this by adding unique position information to each word's embedding using mathematical sine and cosine functions.
The positional encoding formula uses different frequencies for different dimensions:
Even positions: PE(pos, 2i) = sin(pos/10000^(2i/d_model))
Odd positions: PE(pos, 2i+1) = cos(pos/10000^(2i/d_model))
This approach ensures that each position in the sequence receives a unique, learnable representation.
The Decoder: Generating Output Context
Architecture and Purpose
The decoder is responsible for generating the output sequence using both the encoder's representations and previously generated tokens. Like the encoder, it consists of six identical layers, but with additional complexity to handle the generation process.

Diagram of the Transformer architecture showing the Encoder and Decoder components with multi-head attention, normalization, and fully connected layers
Each decoder layer contains three sub-components:
Masked Multi-Head Self-Attention: Prevents the model from "seeing" future tokens during generation, ensuring that predictions only use previously generated information.
Encoder-Decoder Attention: Allows the decoder to focus on relevant parts of the input sequence while generating each output token.
Feed-Forward Neural Network: Similar to the encoder, this applies additional transformations to refine the representations.
Autoregressive Generation
The decoder operates autoregressively, meaning it generates one token at a time using previously generated tokens as context. This process continues until the model produces a complete output sequence.
During training, the decoder learns to predict the next word in a sequence, but during inference, it uses its own predictions as input for subsequent generations.
Supporting Components: The Architectural Foundation
Residual Connections and Layer Normalization
Every sub-layer in both encoder and decoder includes residual connections followed by layer normalization.
Residual connections create "skip connections" that help gradients flow through the network during training. Mathematically, this means: Output = Layer_Output + Input.
Layer normalization stabilizes training by normalizing the activations within each layer. Together, these components enable the construction of deeper, more effective networks.
Feed-Forward Networks
The position-wise feed-forward networks in both encoder and decoder apply the same linear transformations to each position independently. These networks typically expand the dimensionality (e.g., from 512 to 2048) before projecting back to the original size.
The mathematical representation is: FFN(x) = ReLU(W₁x + b₁)W₂ + b₂
This component adds significant learning capacity to the model, allowing it to capture complex, non-linear relationships.
The Context Revolution: Why Transformers Matter
Parallel Processing Advantage
Unlike sequential models like RNNs, Transformers process entire sequences simultaneously. This parallel processing capability dramatically improves training efficiency and enables the model to capture long-range dependencies more effectively.
Global Context Understanding
The attention mechanism allows every word to directly interact with every other word in the sequence. This global connectivity enables Transformers to understand context across entire documents, not just local word relationships.
Scalability and Versatility
The Transformer architecture scales effectively to larger datasets and model sizes. This scalability has enabled the development of large language models with billions of parameters that can perform diverse tasks from translation to creative writing.
Real-World Applications
Transformer encoder-decoder models excel at tasks requiring input-to-output transformation:
Machine Translation: Converting text from one language to another
Text Summarization: Creating concise summaries from longer documents
Question Answering: Generating answers based on input context
Code Generation: Converting natural language descriptions into programming code
The Learning Journey: From Theory to Practice
Understanding Transformer architecture provides the foundation for working with modern AI systems. The encoder-decoder context mechanism represents a fundamental shift in how machines process and generate human language.
For those beginning their journey into large language models and deep learning, mastering these concepts opens doors to understanding cutting-edge AI technologies. The principles learned here apply directly to working with frameworks like PyTorch and building your own transformer-based applications.
The combination of attention mechanisms, positional encoding, and parallel processing creates a powerful architecture that continues to drive innovations in artificial intelligence. As you explore deeper into this field, these fundamental concepts will serve as your guide to understanding and implementing advanced AI systems.
Ready to Master Transformers and Build Your Own LLMs?
This blog post has introduced you to the fascinating world of Transformer architecture, but there's so much more to discover! If you're excited to dive deeper into Large Language Models, attention mechanisms, and hands-on PyTorch implementation, I invite you to join my comprehensive Udemy course.
🚀 "Introduction to LLMs: Transformer, Attention, Deepseek PyTorch"
What you'll learn:
Build Transformer models from scratch using PyTorch
Implement attention mechanisms with real code
Work with cutting-edge models like Deepseek
Master the mathematics behind LLMs
Create your own language generation applications
Perfect for: Beginners to intermediate learners who want to go beyond theory and start building real AI applications.
🎯 Special Limited-Time Offer: Only $9.99!
Transform your understanding from concept to code and join thousands of students already mastering the future of artificial intelligence!
Visit www.srpaitech.com for more AI learning resources and updates.
Comments